استمراراً لمناقشات مشاريع التخرج لبرنامج الذكاء الاصطناعي وعلم البيانات للعام الأكاديمي 2025–2026م، استعرضت جامعة تونتك الدولية للتكنولوجيا مشروعاً بحثياً متميزاً بعنوان:
Arabic Document Layout Analysis Across Hierarchical Levels: Paragraphs, Lines, and Words using a Modified U-Net
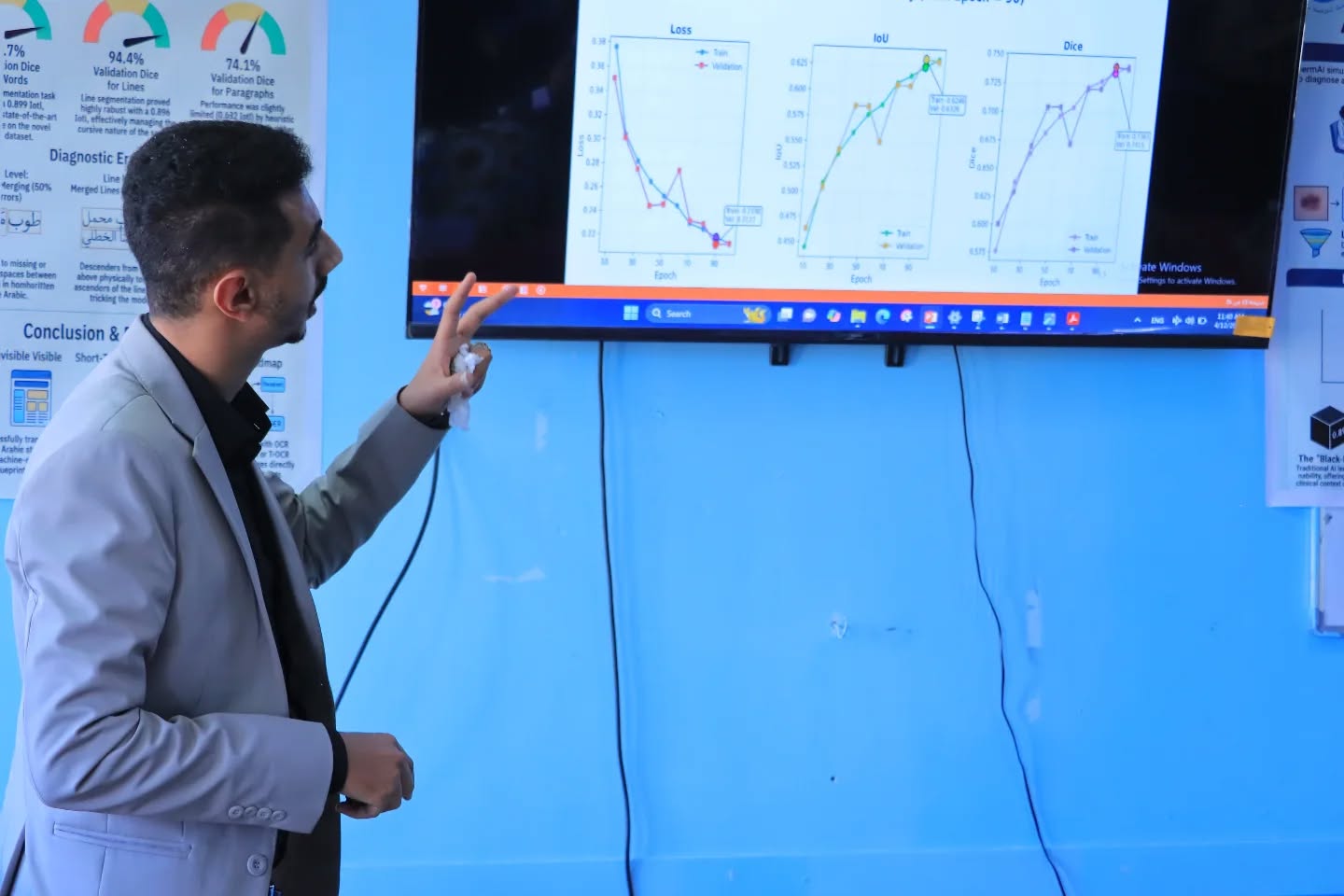
يهدف المشروع إلى تطوير نظام ذكي لتجزئة المستندات العربية على مستويات (الفقرات، الأسطر، والكلمات)، بما يسهم في رفع كفاءة أنظمة التعرف الضوئي على الحروف (OCR). وعمل الفريق على بناء نموذج U-Net معدل، مع دمج دالة خسارة هجينة (Dice Loss & Binary Cross-Entropy) لمعالجة التحديات المرتبطة بترابط الحروف وتداخل البنى النصية في اللغة العربية.
وقد حقق النموذج نتائج قوية في مقياس IoU بلغت 0.896 للأسطر و0.900 للكلمات، متفوقاً على العديد من النتائج السابقة. كما تضمن المشروع مساهمة علمية أصلية عبر تدوين مجموعة بيانات جديدة للكلمات تضم 7,881 صورة، مما يمهد لتطوير حلول تقنية أكثر قوة في مجال المعالجة الرقمية للمستندات.
أعضاء المشروع: هشام الذبحاني، القسام السعيدي، علي الشهاري، أنس الأغبري، نوار العزعزي.
إشراف: د. أمين شايع، أ. محمد القماسي.
لجنة المناقشة الداخلية: د. حمزة جامل، د. أيمن الصبري، أ.د. فضل باعلوي.
لجنة المناقشة الخارجية: أ.د. أحمد سلطان الهجامي، أ.م.د. مالك الجبري.